This post has been much delayed for a number of reasons, namely because some feasible solutions became End of Sale, while others, based on field experience were not practically seen or deployed. In the meantime, other newer solutions which can address some of the issues we discussed earlier have now become available, so here is Part 3.
So back in Part 1, I blogged about considerations for the L2 DCI link for a vSphere Metro Cluster. In Part 2, I covered the potential routing pitfalls of stretching L2 networks across sites.
In Part 3, I’m going to discuss the methods which can be used to workaround the some of issues which we talked about in Part 2. Just to recap, the issues with stretched networks were:
- Asymmetrical traffic flow across DC sites
- Inability of network services (eg firewalls) to handle asymmetric traffic flow
- Lack of VM site-awareness for optimized routing
- Inefficient use of the DCI
VMware NSX Distributed Firewall with Asymmetrical Traffic Flows
In Part 2, I mentioned that it is possible for a VM to move between sites, with the result being that traffic to the VM (ingress traffic) could come in on say DC1, while traffic from the VM (egress traffic) could exit on DC2. Such a situation would cause issues with traditional firewalls, since these need to see traffic flows in both directions in order to allow or deny traffic correctly.
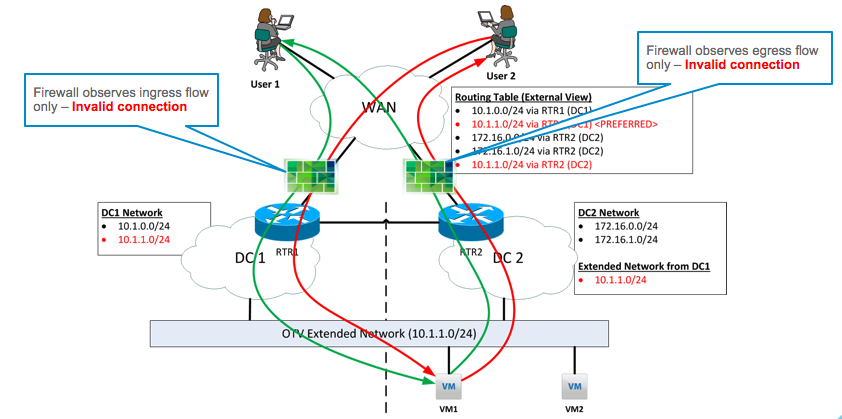
Perimeter Firewalls do not see consistent flow state
In the diagram above, the firewall at DC1 sees the “in” state of the flow from both User 1 and User 2 to VM1, which happens to have vMotioned to DC2. Assuming we’ve tweaked the setup for local egress, the VM will send traffic out via the DC2 router. As a consequence, the firewall at DC2 sees only the “out” state of the flow. This means that firewalls at both sites would observe any or all of the following issues and start dropping traffic because of state inconsistencies:
- Incomplete TCP handshake / termination
- Inconsistent sequence numbers
- Unidirectional traffic flow
With NSX for vSphere, it’s actually possible to deploy a stateful firewall at the VM level using the Distributed Firewall (DFW) feature. NSX DFW works by having security policy defined centrally via NSX, which is then pushed down to corresponding VMs for enforcement at the micro level. With this being the case, we’ve brought the firewall closer to the VM itself by enforcing policy at the vNIC level.
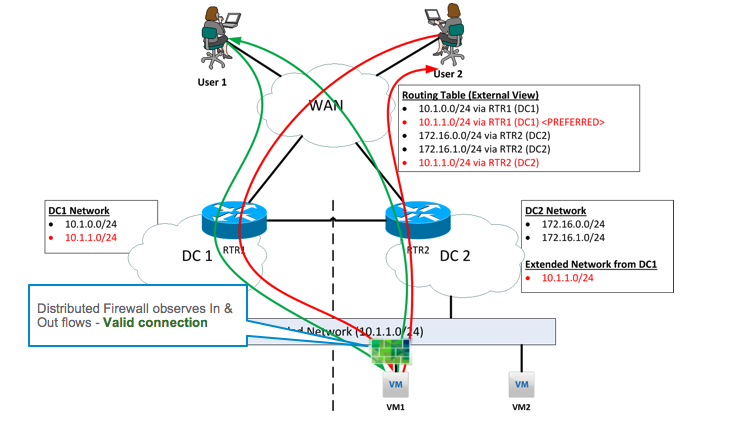
NSX Distributed Firewall sees full flow state
Looking at the diagram above, the network ingress and egress paths of traffic to the VM are still inconsistent. However, the firewall enforcement point is at the vNIC level, which is tied to the VM. At the vNIC level, the DFW will always observe all traffic entering and exiting the VM. The DFW filter will have full information on the network traffic flows of the VM, and be able to appropriately apply stateful firewall policies, regardless of where the VM is or moves to, or how traffic arrives and departs from it. We’ve effectively resolved the problem of stateful perimeter firewalls not working due to not seeing the full traffic flow, by moving the firewall to the VM vNIC.
Other Methods
It bears mentioning that there are/were other methods of addressing some of the other network considerations that come with stretching networks. When writing both Part 1 and 2, I considered writing more on these methods, however it appears that they are not quite feasible in the real world. Here is just a summary of what might have been.
Locator ID Separation Protocol (LISP): As you may have realized, there doesn’t seem to be a solution which has VM site awareness, so there is no way to optimize ingress routing to VMs according to which site they are located on (potentially also reducing DCI traffic). The fact is, LISP was supposed to address this issue, by being able to insert granular routes to VMs depending on where they resided. The biggest challenge with utilizing LISP in order to optimize ingress routing to the VM is that it requires ISPs to support LISP within their infrastructure. It is quite rare to come across such ISPs in the real world. Also, LISP plays a lot with insertion of host routes, which is its own set of network black magic.
DNS Optimization with Cisco ACE Load Balancers: Cisco also developed an orchestration solution utilizing its global and local load balancers to dynamically update DNS A records to point to wherever a VM was vMotioned to. This would enable new connections to directly reach the VM at it’s new location, thus also ensuring new connections do not have to traverse the DCI. It’s really quite a creative hack, though unfortunately the Cisco ACE product line was EoS’ed not long after the solution was published.