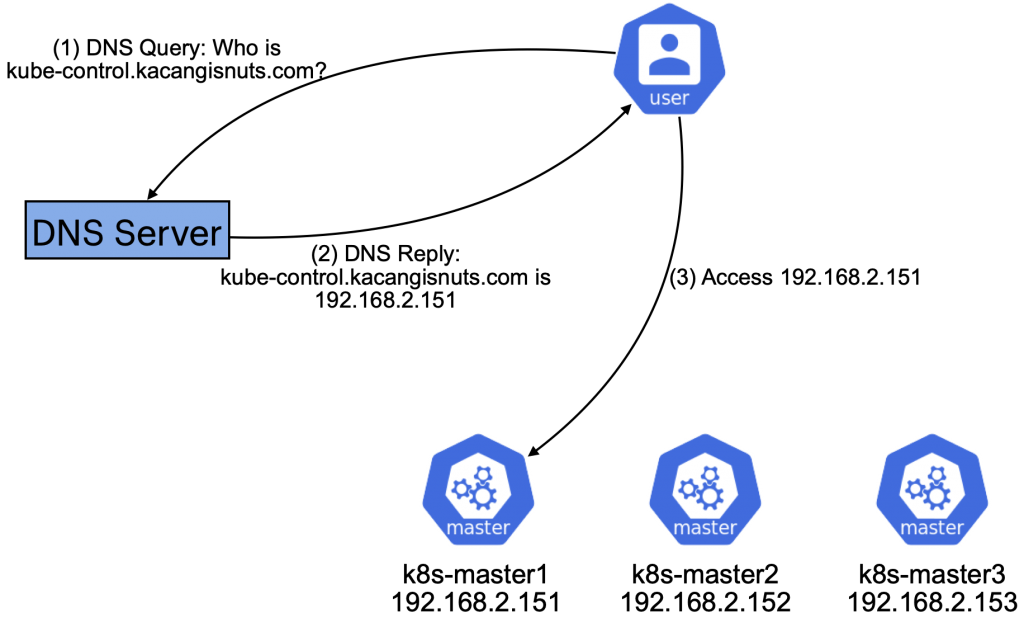
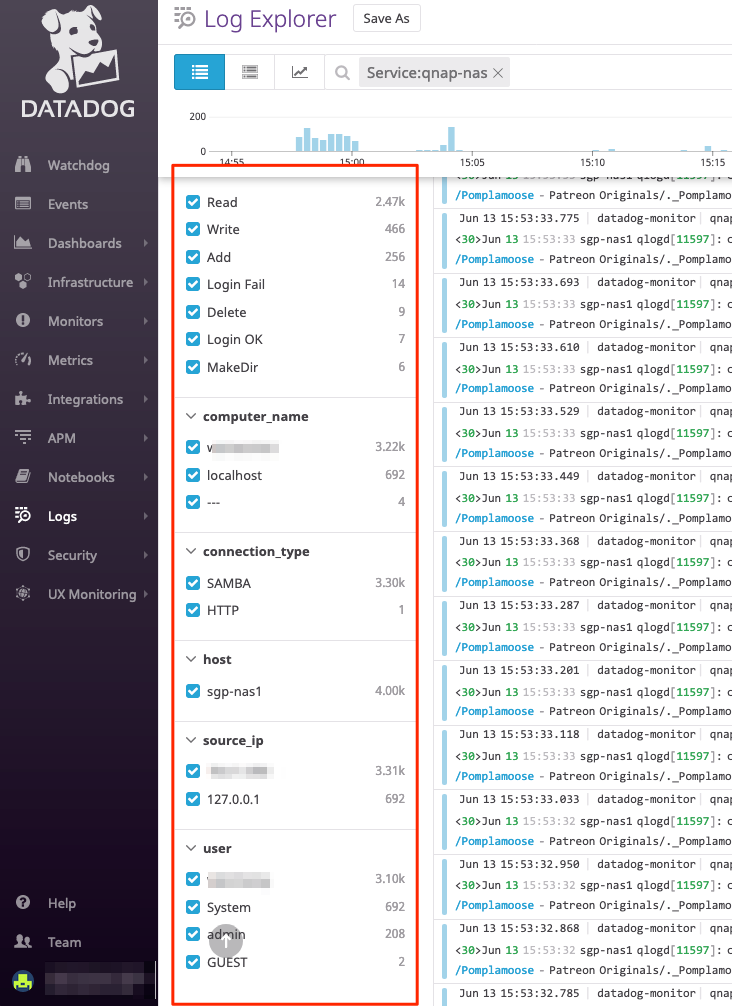
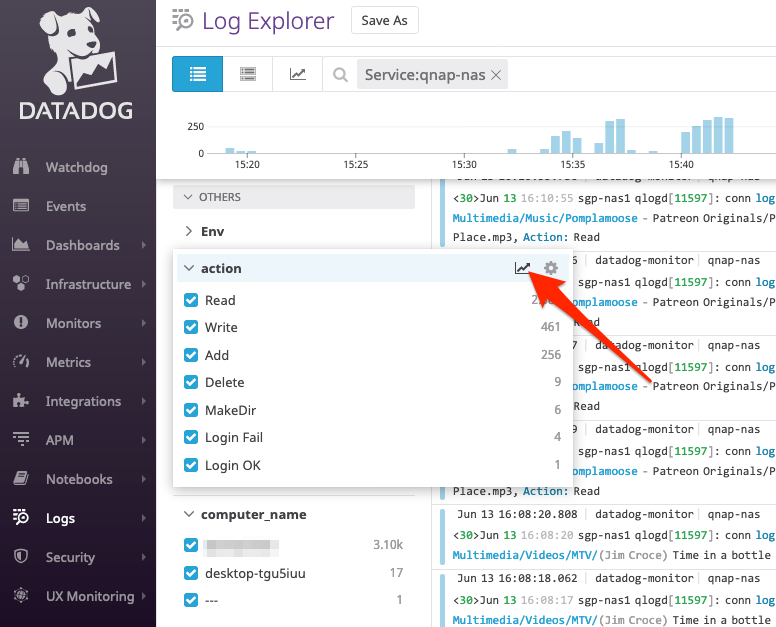
I recently worked on an interesting assignment where NetFlow monitoring was needed for network traffic analysis. Now, the Datadog platform has a rich feature set for analyzing and visualizing just about any type of data, and NetFlow is no different.
The only unusual aspect of the assignment was with collection; We’ll need to use the open source FluentD to collect NetFlows, so in this post I’ll share how FluentD can be used to collect flows for analysis on the Datadog platform.
Brief Overview
I’ve not had a chance to work with FluentD previously, though I’ve heard good things about it. What’s useful about the FluentD agent is that it is modular and extensible with plugins. Particularly, it has both a Netflow Collector source plugin and the Datadog output plugin, which we need. Fun fact, the NetFlow plugin is a certified FluentD plugin, while the Datadog plugin is directly maintained by Datadog developers!
With both of these plugins available, it becomes a matter of configuring FluentD as a NetFlow collector, which will then convert flows to JSON-formatted logs to be submitted to Datadog. It’s really as simple as the diagram below.
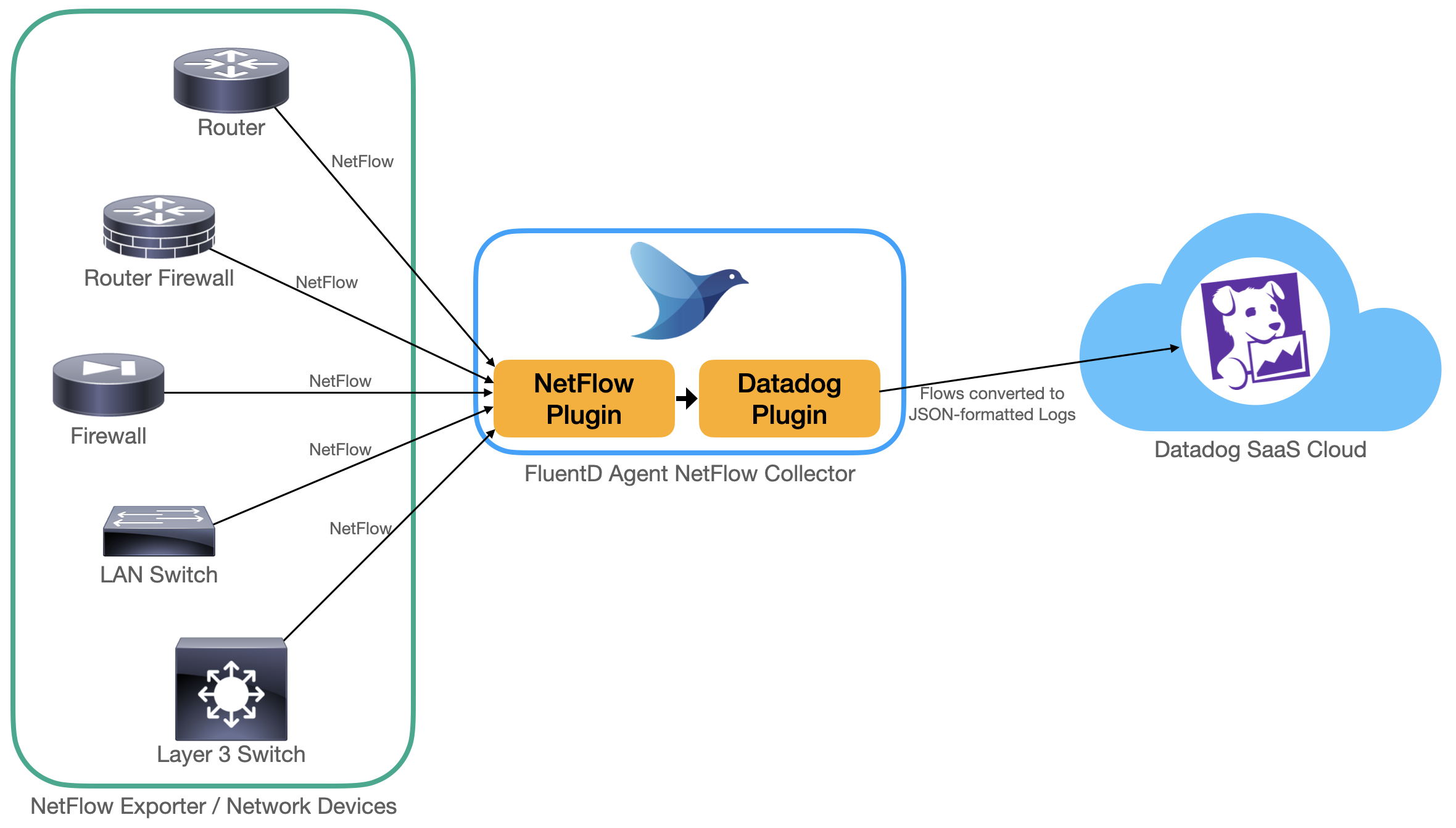
Getting Started
We use a vanilla Ubuntu 18.04 LTS VM, and install the pre-compiled FluentD agent like so:
$ curl -L https://toolbelt.treasuredata.com/sh/install-ubuntu-bionic-td-agent4.sh | shThis installs the latest FluentD agent, and automatically configures systemctl to start it as a service. In case you’re using some other Linux distro, pop over to the FluentD Installation page and follow the distro-specific instructions. I’ve tested a similar set up with RHEL 7, and that works flawlessly too.
Once done, run a quick systemctl check to ensure that the agent is up and running:
$ sudo systemctl status td-agent
● td-agent.service - td-agent: Fluentd based data collector for Treasure Data
Loaded: loaded (/lib/systemd/system/td-agent.service; enabled; vendor preset: enabled)
Active: active (running) since Sun 2021-04-11 10:20:00 UTC; 15s ago
Docs: https://docs.treasuredata.com/articles/td-agent
Process: 17416 ExecStart=/opt/td-agent/bin/fluentd --log $TD_AGENT_LOG_FILE --daemon /var/run/td-agent/td-agent.pid $TD_AGENT_OPTIONS (code=exited, status=0/SUCCESS)
...That all looks hunky dory, but what on earth is all that td-agent business, you ask? It turns out that the company Treasure Data maintains most (all?) stable distribution packages of FluentD. Hence, the FluentD agent is called td-agent in these distributions. You can read more about it in the official FluentD FAQ, but suffice to say that td-agent is equivalent to FluentD for our purposes. Keep in mind though, this does mean that command names, configuration files, etc will carry the td-agent name instead.
Installing the NetFlow Collector Source Plugin
Here, we install the Netflow plugin for FluentD, which turns the FluentD agent in to a NetFlow Collector. Run the following command to install the plugin:
$ sudo /usr/sbin/td-agent-gem install fluent-plugin-netflowInsert the following lines into /etc/td-agent.conf. I use UDP port 5140 to receive flows in my lab, though you can change this to other ports if you like. Remember to point the NetFlow Exporter to the right UDP port later.
<source>
@type netflow
tag datadog.netflow.event
bind 0.0.0.0
port 5140
versions [5, 9]
</source>If you notice, we’re tagging all flows with datadog.netflow.event. This tag will be used by FluentD to match and route the flows to the appropriate plugin for handling. The ‘next steps’, so to speak.
Installing the Datadog Output Plugin
Next, we install the Datadog plugin that will transport the flows as JSON logs to the Datadog cloud for processing and analytics.
$ sudo /usr/sbin/td-agent-gem install fluent-plugin-datadogAdd the following lines into /etc/td-agent.conf, BELOW the NetFlow plugin configuration from the last section, and insert your Datadog API key at the api_key parameter.
<match datadog.netflow.**>
@type datadog
api_key <API KEY>
dd_source 'netflow'
dd_tags ''
<buffer>
@type memory
flush_thread_count 4
flush_interval 3s
chunk_limit_size 5m
chunk_limit_records 500
</buffer>
</match>There are some interesting points about this configuration. Notice first that the match directive looks for datadog.netflow.**. The ** bit is a greedy wildcard, and causes the plugin to process any flows with a tag starting with datadog.netflow. That includes flows collected by the NefFlow plugin, which we earlier configured to apply a datadog.netflow.event tag.
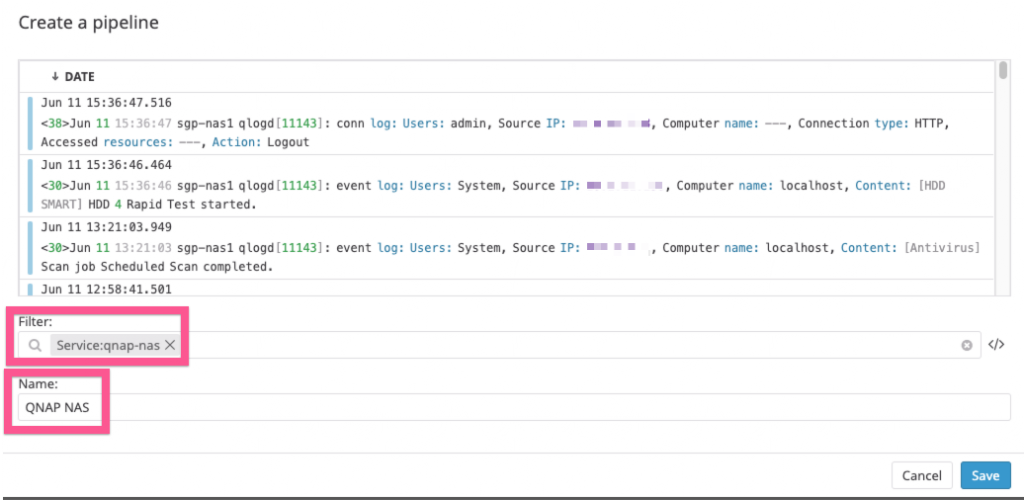
Secondly, notice that dd_source 'netflow' is set, ensuring that flows have the tag source:netflow. It is Datadog’s best practice to use to the source tag as a condition to route logs (flow logs in this case) to the appropriate log pipeline after ingestion. The pipeline then processes, parses and transforms log attributes. Where possible, the pipeline also performs enrichment, for example adding country/city of origin based on a source IP address. This is actually a whole big topic on its own but suffice to say, it is important to configure the source tag appropriately.
Finally, there’s also the ddtag parameter which isn’t used in the example here. This allows the application of custom tags, which could be useful in a larger environments. For example, a large enterprise may have different NetFlow collectors for different zones (DMZ, Internet gateways, branches, data centers, just to name a few), different sites, different clouds etc. Being able to drill into a specific collection context or view using tags is handy to gain extra clarity during analysis.
Now that we’re done with configuring the FluentD agent, make sure to restart the service so the changes take effect.
$ sudo systemctl restart td-agentConfiguring pfSense as a NetFlow Exporter
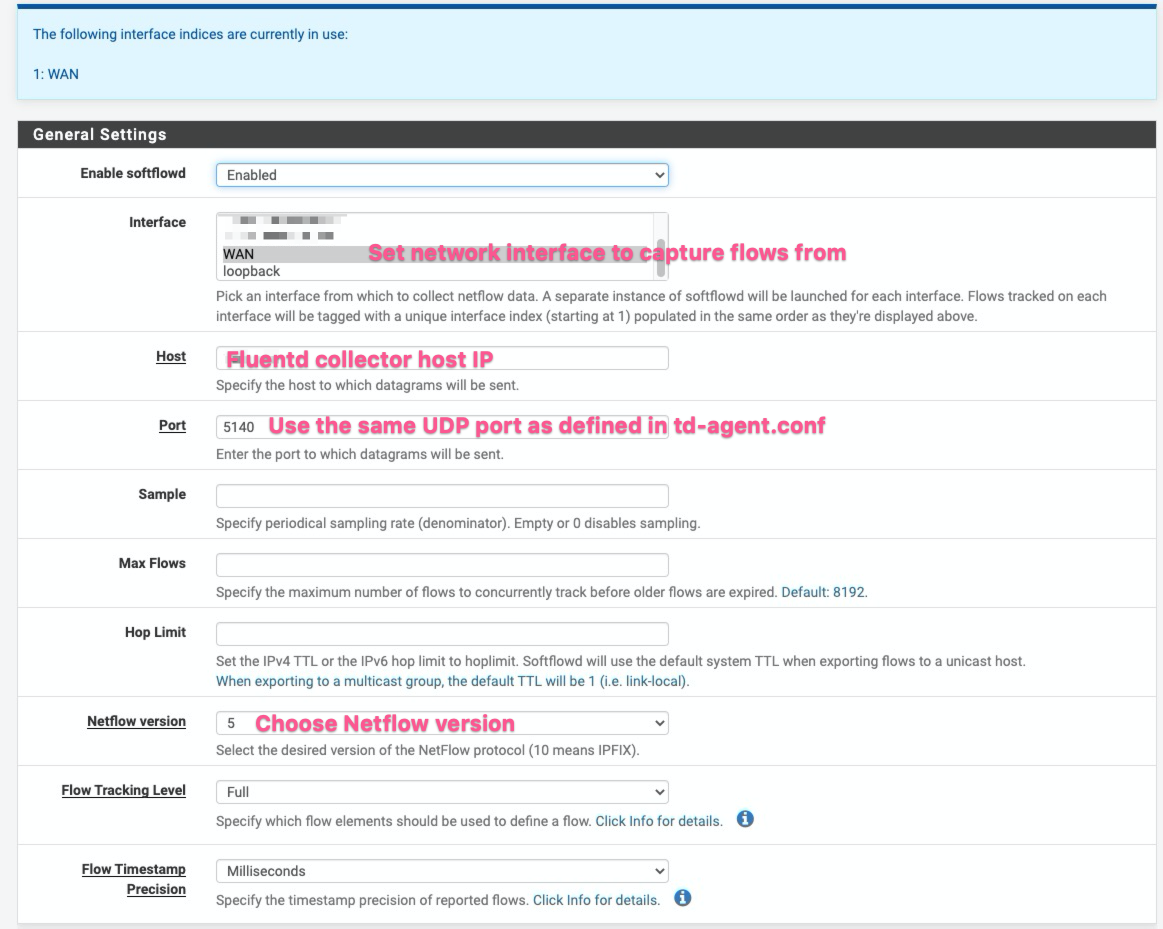
Configuring a network device as a NetFlow Exporter differs depending on the device. In my case, I use a pfSense firewall as my NetFlow exporter. There are more detailed instructions on installing and enabling NetFlow for pfSense using the softflowd plugin, so we won’t go into the details here.
As a sample configuration however, here is how softflowd is set up on my pfSense firewall to export flows. In short, these settings configure the firewall to collect flows traversing the WAN interface, and then to send them as Netflow v5 flows to port 5140 of the FluentD NetFlow Collector.
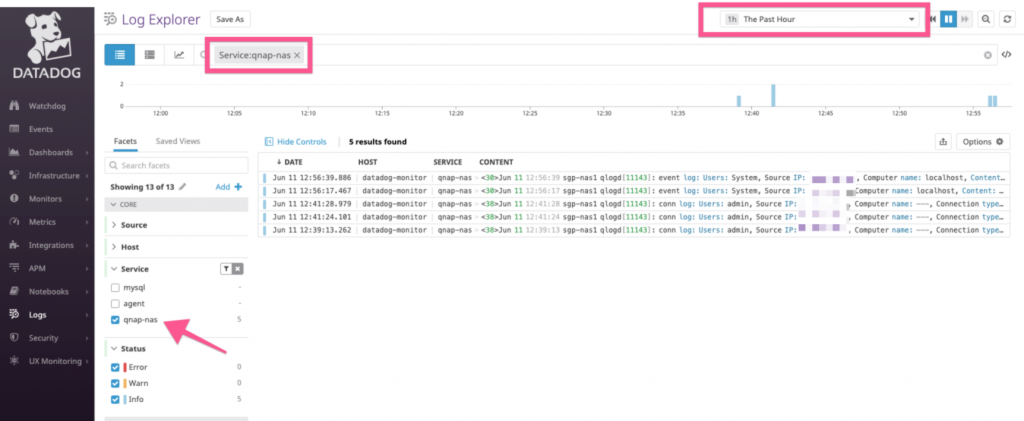
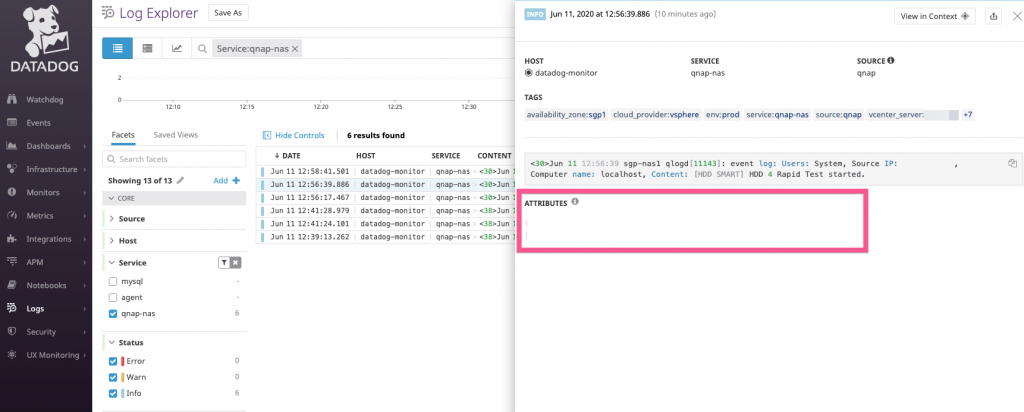
Assuming everything works as advertised, logging into the Datadog Log Explorer screen shows all the NetFlow flow logs that are collected. Popping open any of the flow logs shows the various attributes that were parsed from the flow logs. Unmistakably, the really important ones like Source IP, Source Port, Destination IP, Destination Port, Protocol type, as well as Bytes and Packets transferred are all available.
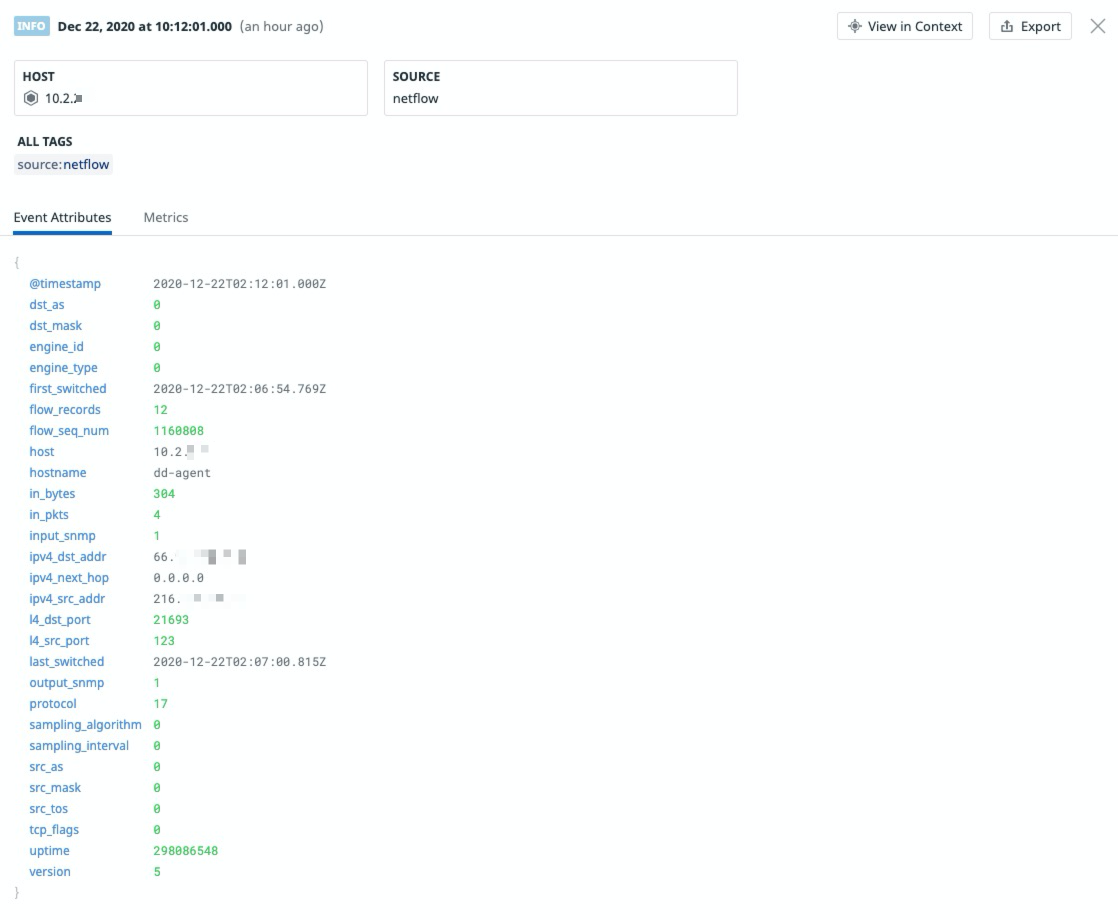
Quick Peek at the NetFlow Dashboard
In the interest of keeping this post on topic around FluentD NetFlow collection, we’ll cover Datadog logs processing some other time. However, as a peek into the possibilities once we’ve got flows ingested, processed and analyzed, here’s a really groovy NetFlow monitoring dashboard that I created.
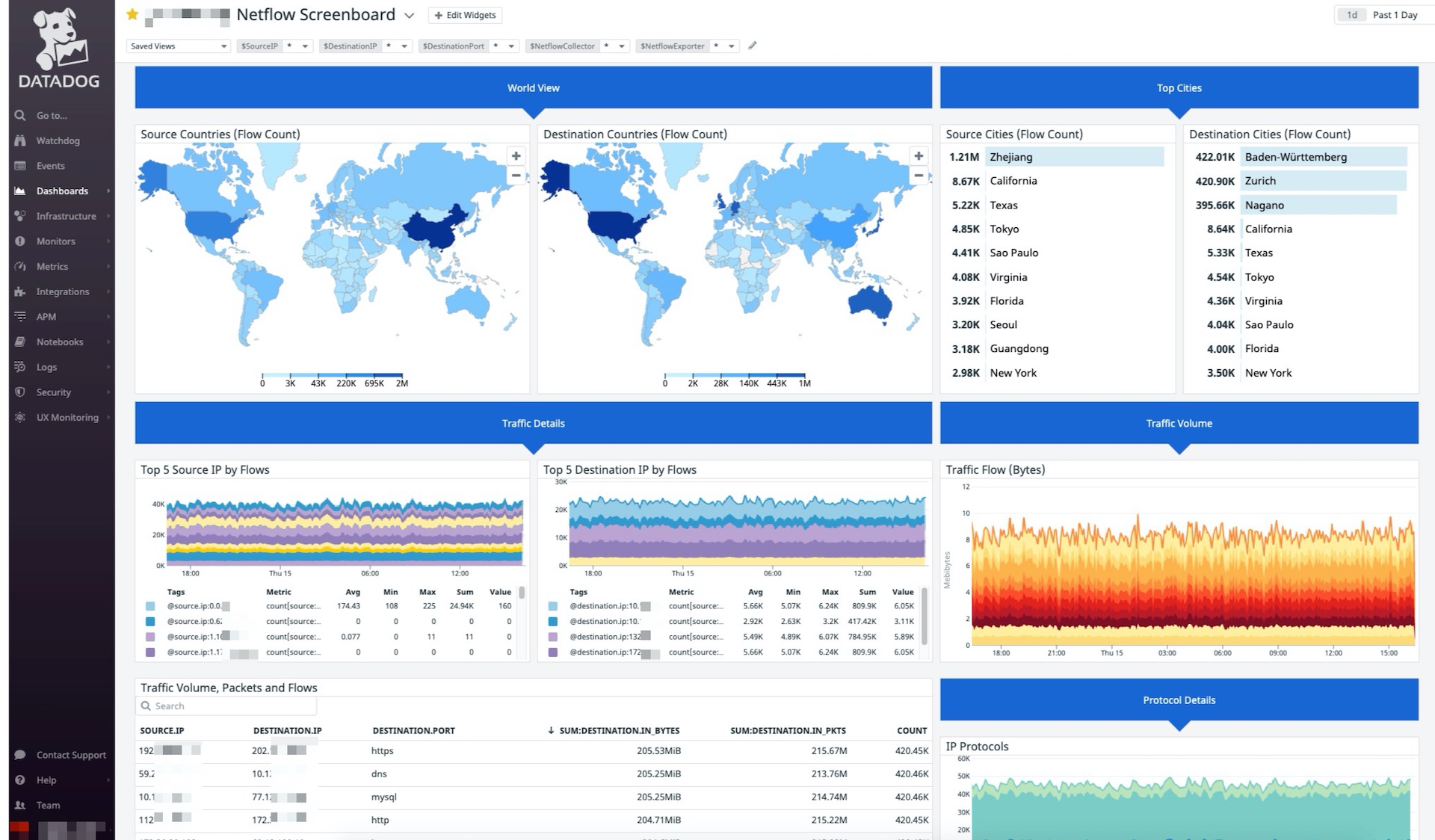
Neat, isn’t it?